DMN's most widely used boxed expression type is the decision table. It's popular because its meaning is intuitive and generally understood without training. The DMN spec imposes certain constraints on the format - what expressions are allowed in a condition cell, for instance. Even when these are ignored by legacy rule engine vendors, the intent of the logic is, for the most part, understood. There is one element of DMN decision tables that is not well understood without a bit of education, however: the hit policy code in the upper left corner. In this post we'll see what it does.
How Decision Tables Work
Consider this decision table that determines whether Loan approval is "Approved" or "Declined" based on inputs Credit risk category and Affordability category. Without any prior DMN knowledge, most users intuitively understand that the columns to the left of the double line are the inputs, the column to the right of the double line is the output, and the numbered rows are the rules. Note here we also see the datatypes of the inputs and output, in this case enumerated allowed values.
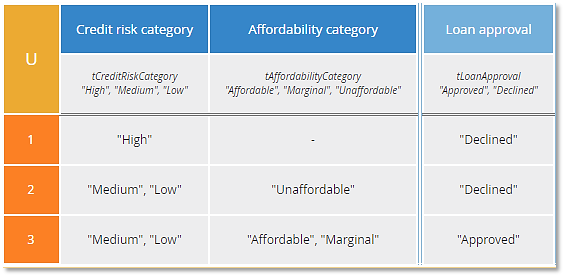
In a rule, each input cell, called an input entry, when combined with the input value creates a Boolean condition, true or false. For example, in rule 1 the column 1 cell is true if Credit risk category is "High". In rule 2, the column 1 cell is true if Credit risk category is either "Medium" or "Low". A hyphen in a condition cell means the cell is true by default, i.e., the input is irrelevant in this rule. For example, in rule 1 the column 2 cell is always true, meaning Affordability category is not used in this rule.
For each rule, if all condition cells evaluate to true, the rule is said to match and the expression in the output cell is selected as the decision table output. Constraints on the inputs such as enumerated values allow you to make sure that the table is complete, meaning for any combination of input values, at least one rule matches. The spec does not require tables to be complete, but it is normally best practice. If it is possible that for some combination of input values, more than one rule matches, those rules are said to overlap. Hit policy, the code in the upper left corner, is used to deal with overlapping rules.
Hit Policy
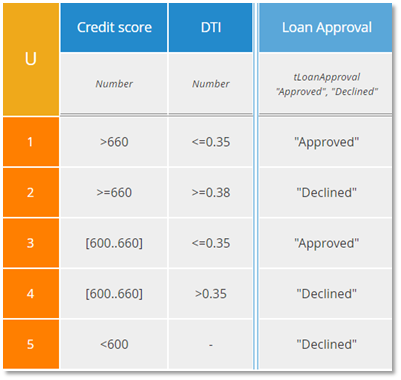
The table above has hit policy U or Unique, meaning rules do not overlap. If you create a decision table with overlapping rules and use hit policy U, that is an error. Some experts maintain you should always strive to create U tables, but often other hit policies are simpler, either easier to construct or requiring fewer rules. For example, consider this table that expresses the identical decision logic:
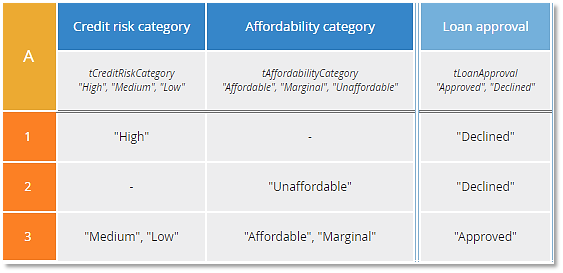
Now rule 2 is simpler because the column 1 condition is hyphen. But notice that if Credit risk category is "High" and Affordability category is "Unaffordable", both rules 1 and 2 match. Those rules overlap. Here the hit policy A (for Any) warns us that rules may overlap, but with A tables overlapping rules must have the same output value. And here they do: "Declined". To me, this table expresses the logic more plainly than the U table: If either Credit risk category is "High" or Affordability category is "Unaffordable", Loan approval is "Declined", otherwise "Approved".
Actually we can make this logic plainer still. Consider the table below:
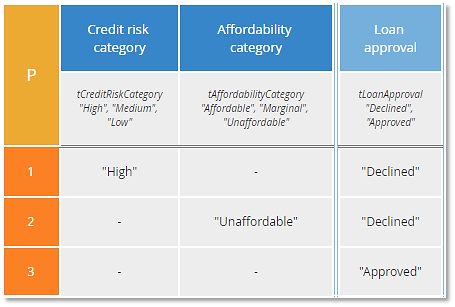
In this table, rule 3 has hyphens in all columns, so it matches for any combination of input values. I call it the "else rule", since it is used for the "otherwise" or "else" condition in the logic. Here we have the hit policy P, or Priority. A P table tells us that overlapping rules may have different output values, and we should select the one with the highest priority. The priority of an output is based on its order in the list of enumerated output values, so P tables can be used only with enumerated output values. Moreover, the output of an else rule must be the lowest priority value, since any rules with lower priority output could never be selected. Note that here we had to modify the output type tLoanApproval to make "Approved" the lowest priority value.
Actually, we can use a P table to model the same decision logic with only 2 rules, as you see below:

This says if Credit risk category is either "Medium" or "Low" and Affordability category is either "Affordable" or "Marginal", Loan approval is "Approved", otherwise "Declined". Now "Declined" is the lowest priority output. Based on the allowed values of the inputs, the logic is identical to the previous tables. The second P table has fewer rules than the first one, but is it better? That's hard to say. I would tend to favor the first one because if you report which rule was selected, it reveals the specific reason why Loan approval was "Declined", whereas the second one does not.
Although some decision table experts strongly dislike P tables, I find them extremely useful. The logic is generally at least as simple and plain as the equivalent A table and simpler than the equivalent U table.
Hit policy F (for First) also allows overlapping rules with different output values and does not require enumerated outputs. It says select the first matching rule in the table. Although allowed by the spec, it violates the general principle that decision table logic should be declarative, independent of the order of the rules. As such it is semi-deprecated, and I ask my students always to use a P table instead.
Hit policy C (for Collect) assumes overlapping rules, and says the output is the collection, or list, of their outputs. Because the ordering in that list is unspecified, the spec also defines hit policy O, meaning collect in priority order, and R, meaning collect in rule order (like First). I have never seen hit policy O or R used in the wild.
Misleading Rules
P tables do not require an else rule, but without an else rule P tables may contain "misleading" rules. I suspect this is why some experts disdain them. Below is an example:
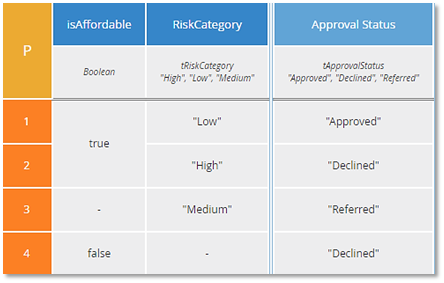
Look at this table and tell me, under what conditions is Approval Status "Referred"? Did you say when RiskCategory is "Medium"? That is incorrect. The correct answer is when RiskCategory is "Medium" and isAffordable is true. When RiskCategory is "Medium" and isAffordable is false, the output is "Declined", because "Declined" is higher priority than "Referred". Rules 3 and 4 are "misleading" because they are non-else rules with a hyphen in some input and the output of one of them (Rule 4) is not lowest priority. Yes, that's a little confusing.
Decision Table Analysis
The hit policy code is assigned by the modeler, and as we've seen, it's possible to make a mistake:- A U table must not have overlapping rules.
- In an A table, overlapping rules must have the same output value.
- In a P table, the output must have enumerated output values.
- In a P table, an else rule output must be the lowest priority value.
- Incomplete tables, with gaps in the rules, meaning some allowed combination of input values matches no rule.
- Subsumption, multiple rules that could be combined into a single rule. Best practice says tables should be fully contracted.
- A table with no overlapping rules assigned to hit policy A or P.
- A P table with misleading rules.
In the Trisotech Decision Modeler, the tool can check for mistakes like these using a feature called Method and Style Decision Table Analysis. For this table it produces the error list below:

Using this feature ensures that your decision tables are well-formed and consistent with best practice.
Become a DMN Professional
If you want to use DMN in your work, you really need training. Our DMN Method and Style training takes you through not only the basics - DRDs and decision tables, including hit policy - but the other features you will need in real-world decision models: FEEL expressions, BKMs, contexts, and all the rest. The course is hands-on with the tools. You get 60 days use of the Trisotech Decision Modeler, which you use to do in-class exercises and your post-class certification model. And you can go on from there to our Low-Code Business Automation course, since Trisotech uses DMN to make BPMN executable with zero programming. We have an attractive bundle of those two courses together. Check it out.