In a post last summer, I began to question the value of assigning constraints like a range of allowed values to datatypes in DMN, in favor of performing data validation using a decision table inside the decision model. There were a few reasons for this:
- Data values violating the constraint behaved differently in decision tables and literal expressions. Decision tables produced a runtime error, while the same value in a literal expression might be ignored or simply generate a null result. That's because type checking in the runtime engine was turned on for decision tables but turned off otherwise.
- The constraints possible in an item definition were limited: basically either a list of enumerated values or a numeric range. Many real-world constraints - an integer value, for instance - could not be type-checked, so in practice you always needed some data validation inside the decision model anyway.
- At that time I admittedly was biased against runtime errors, as the error message returned by the runtime was anything but user-friendly. With data validation using a decision table, modelers could define their own, more helpful error messages.
The root of the problem is this: You can say some input data conforms to a certain datatype, but you cannot guarantee that an invoking client will actually provide that. It could be an invalid value or missing entirely. Without type checking, your logic may initially produce null but downstream that null will likely generate a cryptic runtime error. So you really want to catch the problem up front.
Enhanced Constraint Definition
Prior to version 11.4, the allowed constraints on an item definition mirrored the simple unary tests allowed in a decision table input entry. You could specify either an enumerated list or a numeric range, but that's it. Now constraints can be defined as any generalized unary test, meaning any FEEL expression, replacing the variable name with the ? character. For example, to specify item definition tInteger as an integer, you can say it is basic type Number with the constraint ? = floor(?). And here is something interesting: An expression like that used in a decision table requires first ensuring that the value is a Number. If it is Text or null, the floor() function will return a runtime error. For example, in a decision table rule validating integer myInt, where true returns an error message, you would need something like if ? instance of Number then not(?=floor(?)) else true. But with type checking on tInteger as defined above, you don't need the instance of condition. Type checking generates an appropriate error message when the base type is incorrect, simplifying the type check expressions. Even better, with each constraint specified for an item definition, modelers can define their own error message and unique error code, simplifying documentation and training.Here is an example. Input data User is structured type tUser with three components: Name, which is text; ID, text with the format A followed by 5 digits; and Cost Center, a positive integer. All three components are required. Now in the item definition dialog, you can add a constraint expression as a generalized unary test, assign it a unique Validation Code, and specify the Validation message returned on an error. Below you see the item definition for tName. Here we actually defined two expressions, one to test for a null value and a second one to test for an empty string. If an invoking client omits Name entirely, the value is null. But when you test it in the DMN modeling environment, leaving Name blank in the html form does not produce null but the empty string. (You can get it to produce null by clicking Delete in that field.) So you really need to test both conditions. It turns out null returns both error messages.
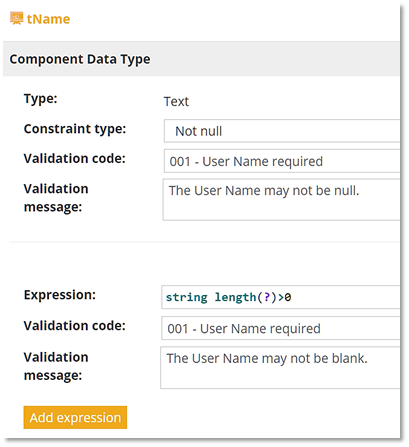
The type definitions for all three components are shown below. ID uses the matches function, which checks the value against a regular expression. We don't need to test for null or empty string explicitly, as both of those will trigger the error. And Cost Center uses the integer test we discussed previously.

Type Checking in Operation
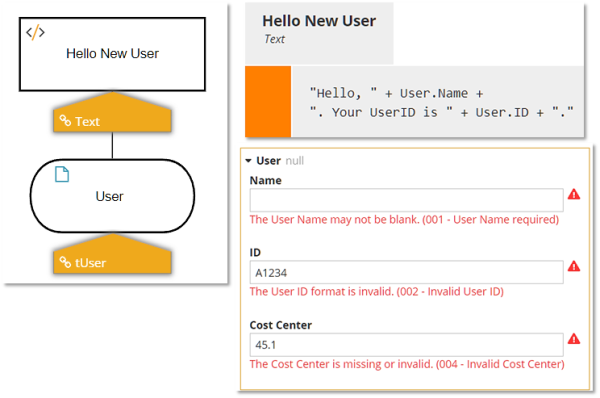
Let's see what happens with invalid data. Below you see the simple decision Hello New User, which returns a welcome message. What if we run it in Execution/Test with all three fields blank? The data is never submitted to the decision. Instead, the modeler-defined Validation Message and Validation Code are shown in red below each invalid field. If this decision service was deployed, a call to it omitting all three elements would return an html 400 error message, also containing the modeler-defined Validation Message and Validation Code.
Validation Levels
This is all very nice! But it's quite a change from the way the software worked previously. For that reason, you can set the validation level in the tool under File/Preferences.
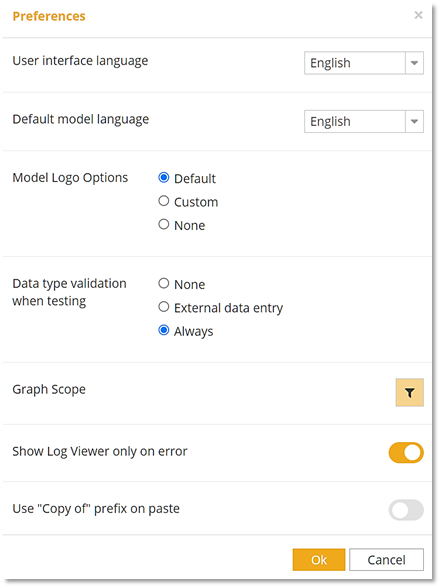
As you can see, you have three choices. None turns off type checking; it is how the software worked previously. External data entry effectively checks only input data. If you've thoroughly tested your model, that's the only place invalid data is going to appear. Always type checks everything. Trisotech recommends using Always until you've thoroughly tested your model.
A Benefit for Students
In my DMN training, I am beginning to see the value of that. To be certified, students must create a decision model containing certain required elements, including some advanced ones like iteration and filter. And they often make mistakes with the type definitions, not so much in the input data but in the decision logic, for example, when a decision's value expression does not produce data consistent with the assigned type. Now, instead of me telling the student about this problem, the software does it for me automatically! It's too early to tell whether students like that or not, but in the end it's a big help to everyone.