In my previous posts on Business Automation, my focus has been on straight-through processes, since this is the sweet spot of the Trisotech platform. But even there, occasionally you need some human input, and that is where User tasks come in. User interaction is not a primary consideration in Trisotech BPMN, so the User task implementation is fairly basic. Even so, how to model User tasks confused me until recently. I think this is because of some default shortcuts in the modeling intended to simplify things. In this post I will demonstrate the "Method and Style" way of modeling the User tasks, which will explain what the default shortcuts are doing.
Trisotech intentionally avoids the conventional User task implementation based on a task list and form builder found in many BPM platforms. Instead, their intent is that user interaction is "decentralized and elective." This means no need to access a task list; each user selects their preferred channel for task delivery, such as email, MS Teams, etc. Currently the only channel available is email. The assigned task performer receives an email with instructions and the task data inputs displayed in HTML tables. A button labeled Complete task opens up an HTML form where the performer can enter the task output data or load it from a file. Clicking Run returns the task output to the process, which continues from there.
So let's see how to configure that in the Workflow Modeler, using the simple example below:
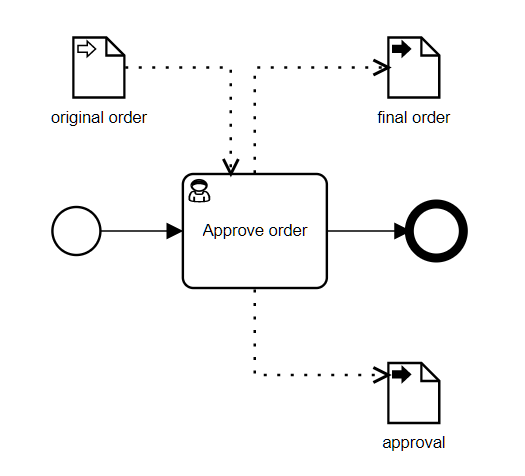
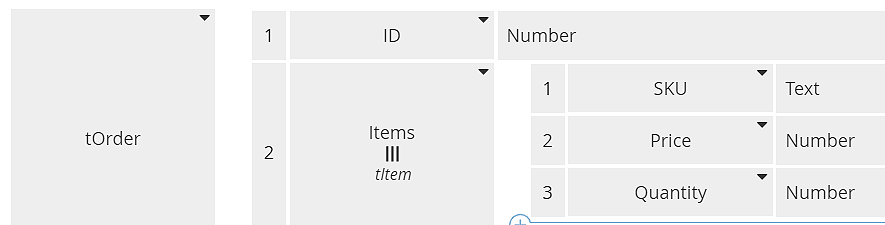
Here the process data input original order and data output final order are both type tOrder, shown below.
The task performer can edit the order and either Approve or Reject it. This is about as simple as you can get.
Data Mapping
Configuration of this task in the Workflow Modeler uses the Data Mapping attribute. Here original order, final order, and approval are process variables from the BPMN diagram. In addition, the task itself has internal variables. By default, the tool defines some internal variables as copies of the process variables, but this shortcut was confusing to me. So I prefer to explicitly define the internal variables and mappings. The input mapping is shown below.
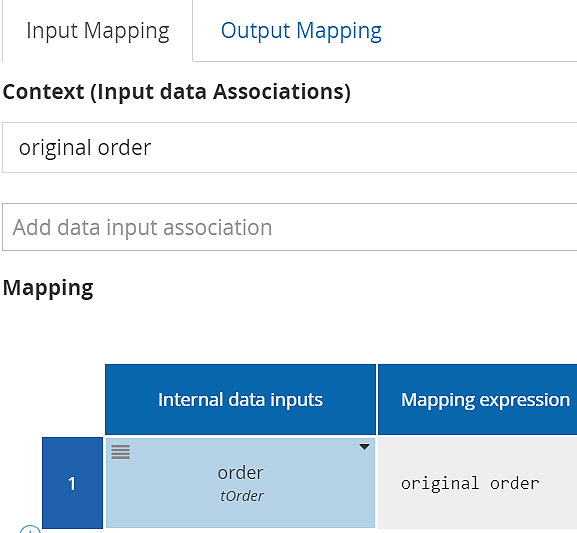
The section labeled Context (Input data Associations) lists the process variables with incoming data associations. The Mapping section is where you define in the left column any internal task variables displayed as inputs to the task performer, and their value mappings from the input data associations. We can call those task input variables. Here I've defined a task input variable named order, also type tOrder, and simply copied original order to this variable, but the mapping could be more complicated.
The output mapping is shown here:

The section labeled Context (Inner data outputs) is where you define internal task variables modified in the task. Let's call those task output variables. Here I have defined task output variables order, type tOrder, and signoff, type tApproval (enumeration "Approved" or "Rejected"). Since task output variable order has the same name as a task input variable, they are considered the same variable, and the mapped input values are passed to the task output variable, which is editable as part of completing the task.
The Mapping section lists process variables linked by data output associations in the left column, and their mappings from the task output variables on the right. Here order is passed to process variable final order, and signoff is passed to process variable approval. While it is not necessary to do so, I intentionally gave the internal task variables and process variables different names, in order to clearly illustrate the data mapping.
Runtime
At runtime, the performer receives an email that displays task input variable order.
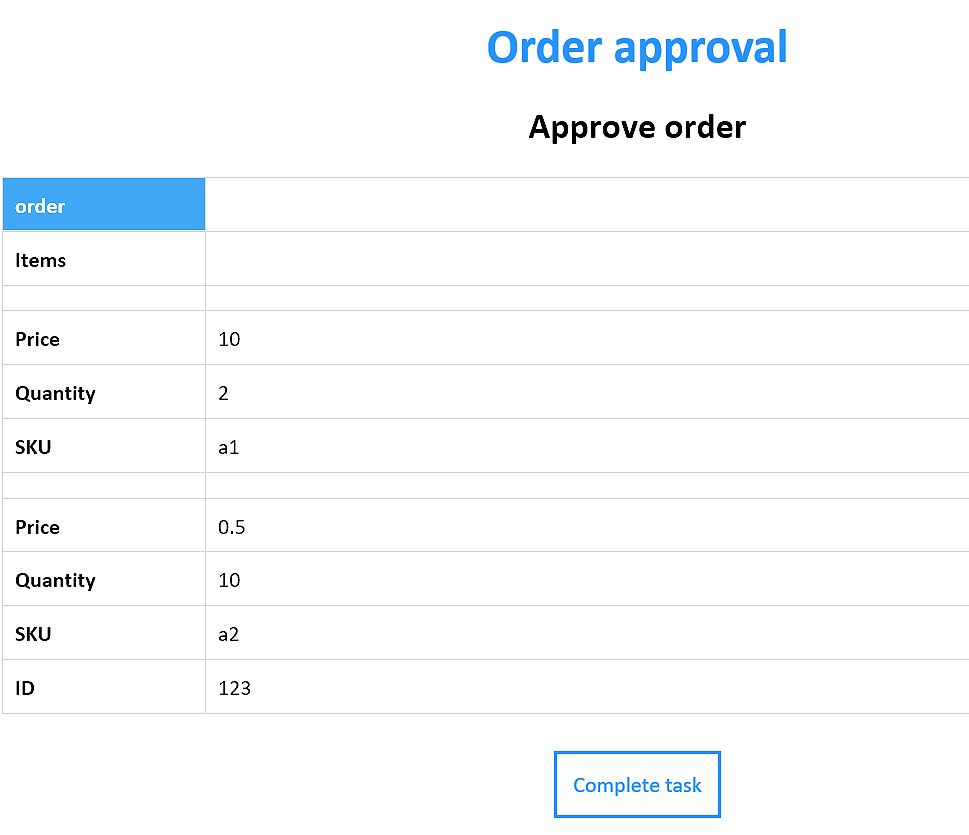
Clicking Complete task then displays an HTML form with two sections: at the top, the Information section shows the task input variable order, and below it is an editable form for completion of the task output variables, the table order and a pick-list field signoff. The performer can make edits to the output order table, select the value of signoff, and complete the task by clicking Run. This passes the task output variable values to their associated process variables, and the process continues.
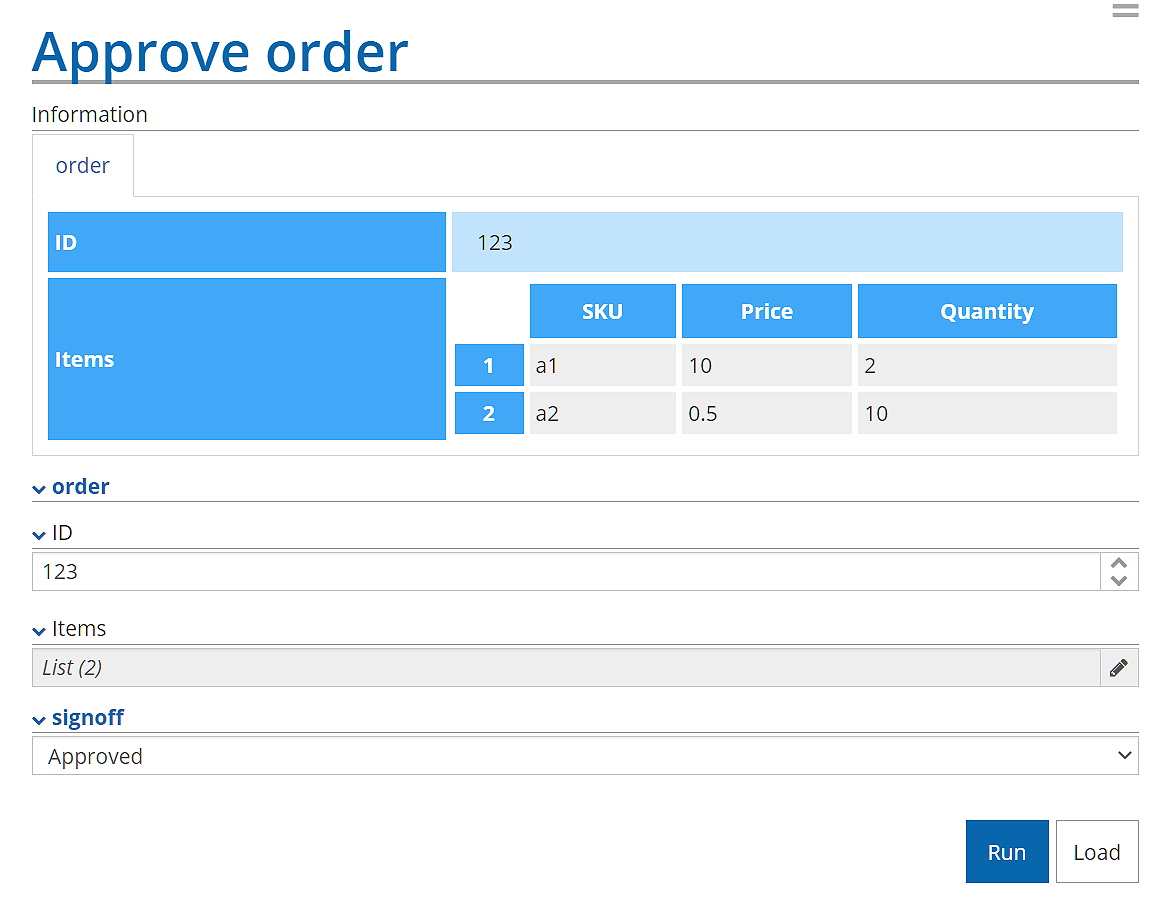
The UI is not fancy, but it is sufficient for occasional human input to Business Automation processes.
The Default Shortcut
To simplify the modeling, the tool behind the scenes creates the internal task input and output variables with identity mappings to the input and output data associations. With this shortcut, you can omit configuring data mappings completely and still have an executable model, but this can give the false impression that the task output must be keyed in manually. This is illustrated below.The default input mapping looks like this:
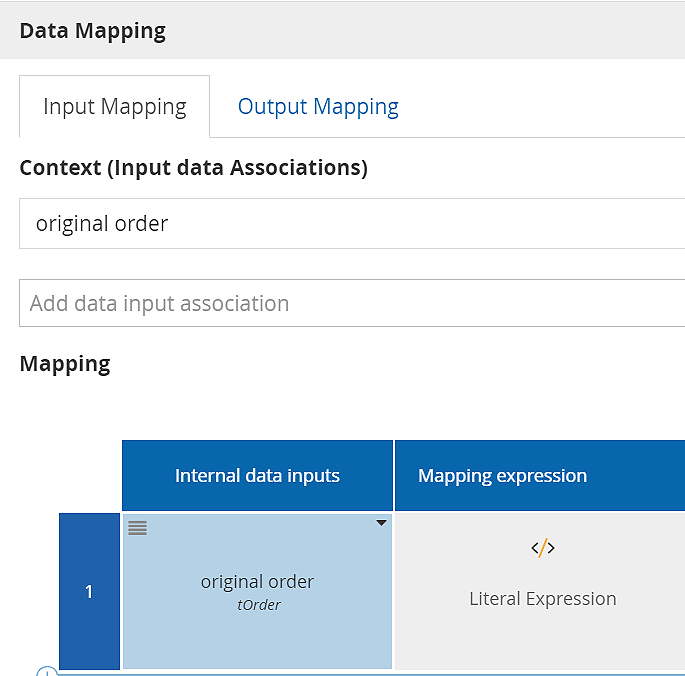
Note that the tool has automatically created a task input variable original order, matching a data input association of that name, and left the mapping blank. At runtime the process variable original order is mapped to it.
The default output mapping looks like this:

Again, the tool has created task output variables identical to the output data associations and left the mapping blank. Making no changes, you can publish the model and the task is executable. But at runtime, when the performer clicks Complete task, he gets this:
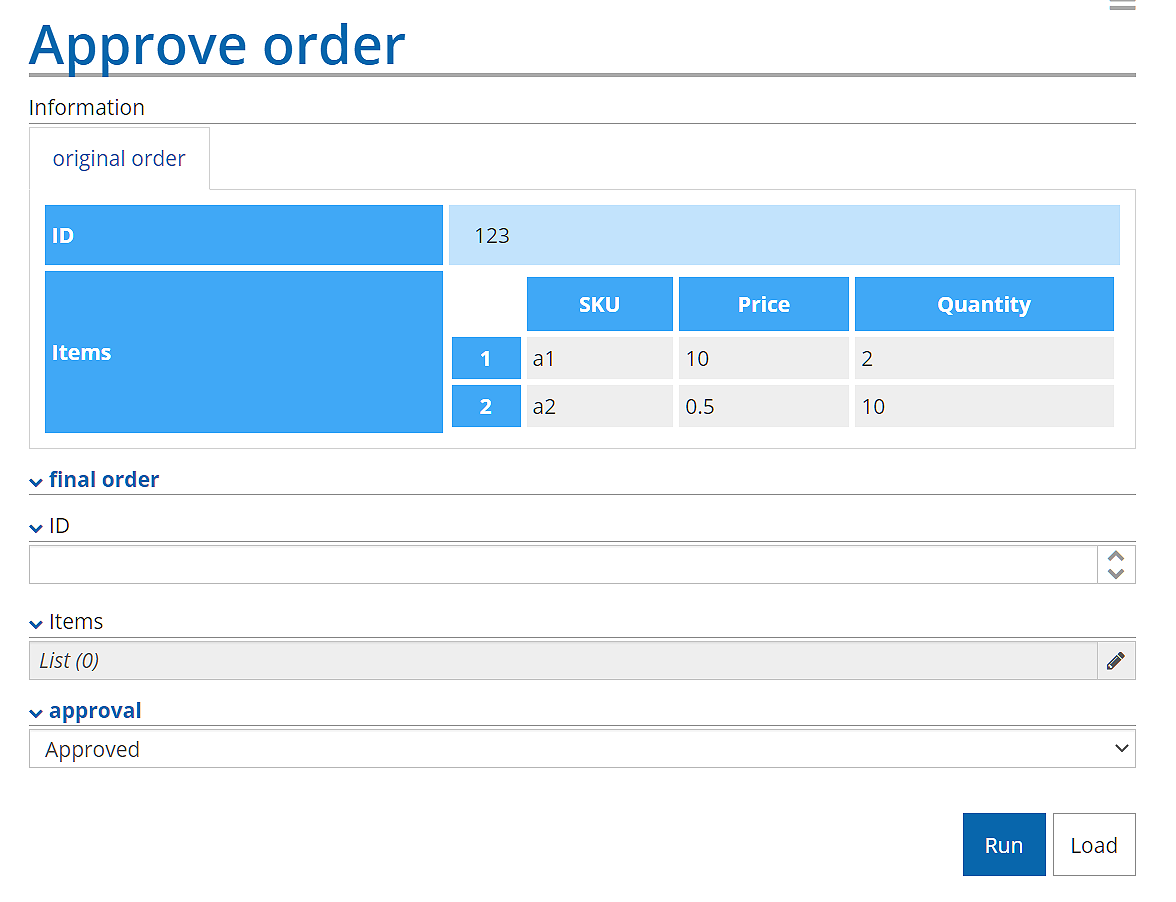
Note that the input values are not copied to the output. They must be keyed in again. Sometimes this is what you want, but not in this case.
This default shortcut is what confused me for a long time, but the key takeaway is you don't have to use it:
To copy task data input to editable task data output, you just need to configure a task input variable and task output variable with the same name.