A critical piece of what makes DMN accessible to business users is its expression language FEEL. FEEL variable names are business-friendly. Because they are simply the labels of the shapes in the Decision Requirements Diagram (DRD), FEEL names may contain spaces and other punctuation not allowed by other expression languages. OK, you already know this.
But when you publish a DMN model as a collection of executable decision services, a non-DMN client can't invoke it using FEEL. The service inputs must be provided in XML or JSON format, and the outputs are returned in those formats as well. If you're using Trisotech Decision Modeler, the tool provides a good bit of help, including automatically mapping XML and JSON inputs to FEEL, and templates that suggest the proper XML or JSON structure required as service inputs. But for certain things you're on your own. In this post I'll try to clear the air.
As a data definition language, FEEL is considerably more limited than XML Schema (XSD). For example, XSD has many different number types; FEEL has just one. XSD supports many different constraints on strings; FEEL just supports enumerated values and defined ranges of numbers or dates. XSD supports multiple cardinality specifications, including optional; FEEL has no conception of optional elements or number of occurrences other than 1 or "multiple", i.e., a list. Nevertheless, Trisotech automatically creates an equivalent (or as close as possible) FEEL item definition when you import an XSD file, and automatically maps XML inputs conforming to that schema to the generated FEEL type. That mapping ignores namespaces and case, generates null values for omitted optional elements, and can even map XML names without spaces to their FEEL equivalent names including spaces!
All that is really helpful because many of the data sources you need in your decision models are already defined as XML conforming to some XSD. By associating your input data element with the generated FEEL type, you can easily model your decision logic using FEEL, and invoke the resulting decision service using the original XML!
That's fine when you start with XML input data. But more often, modelers start with FEEL input data, which allow spaces in the names. Since XML variable names cannot contain spaces, this would seem to present a problem for calling a decision service. Somehow you need to create XML equivalent to FEEL input data with spaces in the names. The DMN task force in OMG has so far resisted standardizing a way to do this, but the DMN Technology Compatibility Kit (TCK), a working group charged with testing conformance to DMN semantics in execution, has done so, and Trisotech supports this alternative XML format as well. When calling a decision service in the Trisotech Cloud, XML input data in either format may be used.
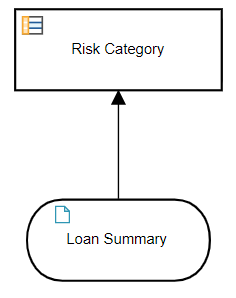
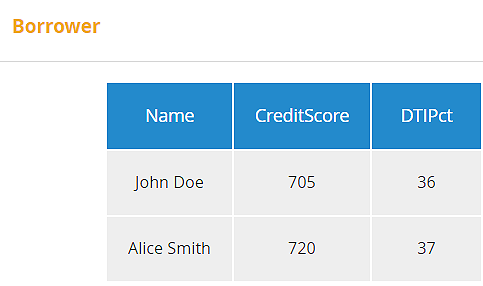
Let's make this clearer with a simple mortgage example, shown in the DRD below. This decision model rates the Risk Category of a loan application based on summary data: Loan amount, loan-t0-value ratio LTV, and for each Borrower, debt-to-income ratio (DTI) and credit score.
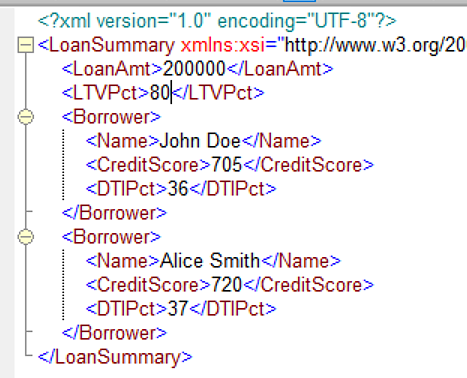
Source data in mortgage applications often is provided consistent with the Mortgage Bankers Association MISMO XSD. That is a large and unwieldy schema, so to illustrate here we use a simpler one, shown below.
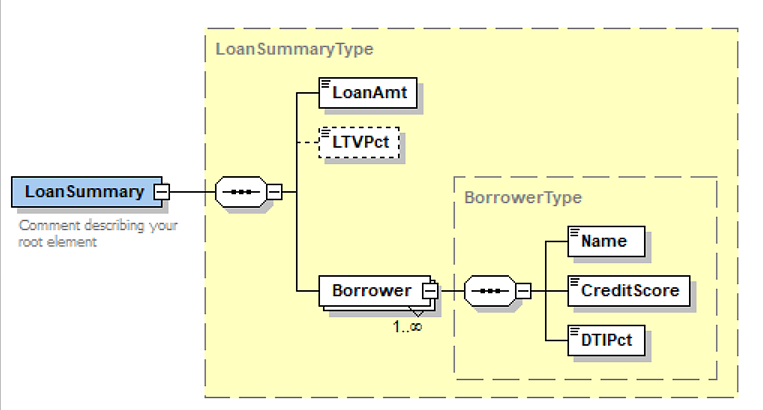
A few things to note about the XML variable LoanSummary:
- None of the components of this structure have spaces in their names; they are not allowed in XML elements.
- Components with solid outlines are required elements; those with dotted outline are optional. So component LTVPct may be omitted in some instances. FEEL does not have the concept of optional components.
- Another difference, not obvious from the schema, is that XML does not have the concept of lists. Instead it has sequences, which are always flat, so unlike in FEEL there is no distinction between a list with one item and the item itself.

We assign our input data Loan Summary to this type. Note the component names have no spaces, so they are valid XML names, although our input data element itself does contain a space. Although I haven't done it here, I could have modified the component names in the item definition: Loan Amt instead of LoanAmt, for example, and at runtime the tool would automatically map the XML element LoanAmt to the FEEL component Loan Amt. That's pretty cool!
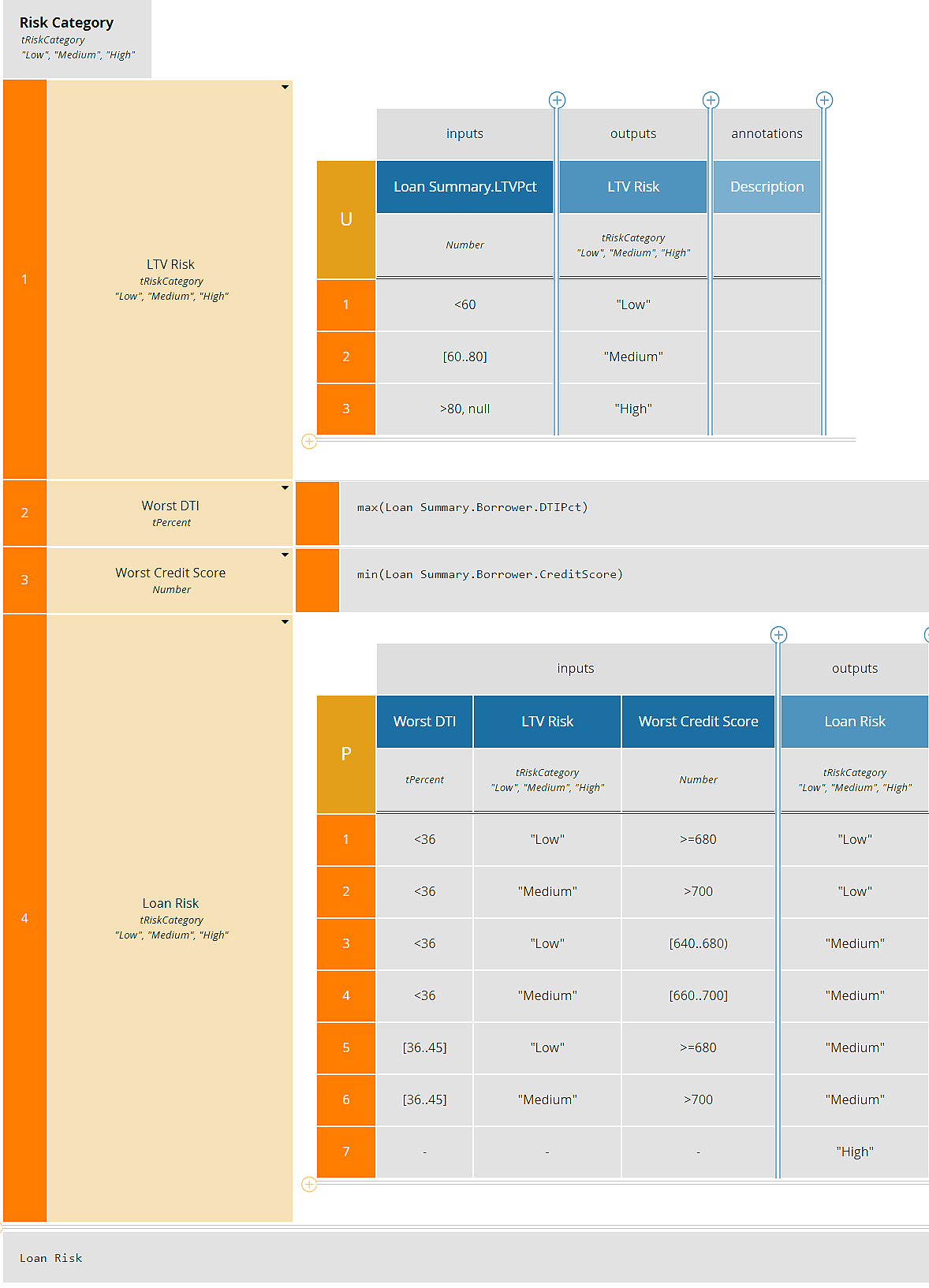
The decision logic, admittedly oversimplified, is shown in the boxed context below. Note that most of the variables used in the logic contain spaces in the names, except for components of the input data Loan Summary. Also note that context entry LTV Risk must account for the possibility that input data component LTVPct is omitted, i.e., null.
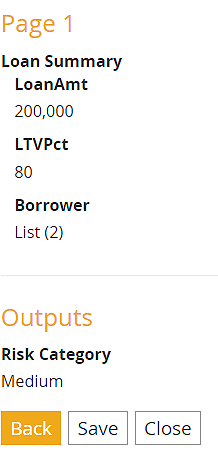
In Trisotech Decision Modeler, we can test the logic in the Execution/Test panel, here giving the result "Medium".
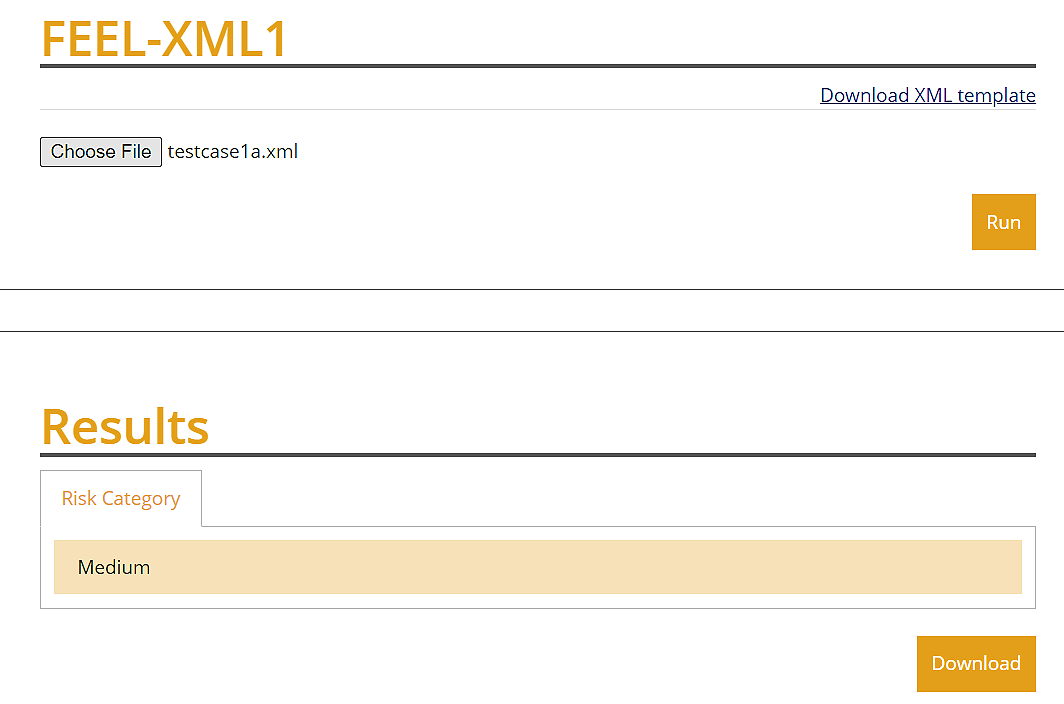
Once we are satisfied that our logic is correct, in one click we can publish our model to the Trisotech Service Library in the cloud as a REST service. To invoke this service from an external client, we simply pass it XML data consistent with our original schema. In this case, our source data was already in this format, so it's quite convenient.
When we execute the service with this XML input, not surprisingly, we get the same result:
The situation is a little different if we defined our decision model using FEEL for the input data. When we publish it as a REST service, we still will need to invoke it using XML or JSON, but in this case, we need to create the XML or JSON ourselves.
The Trisotech Service Library gives us a bit of help here in the form of XML and JSON templates. Notice in the figure above a link Download XML template. Clicking that downloads a skeleton XML file consistent not with the original XSD but with the alternative TCK format! The TCK XML has the advantage that element names may contain spaces, and since we started with FEEL that's just what we want. It looks like this:

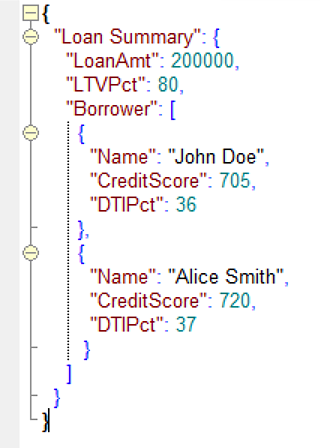
This looks nothing like the original XSD. Now the variable names are no longer XML element names but values of the attribute name, and thus may contain spaces. And because Borrower may occur multiple times, the new schema must declare it as a list. Even though LTVPct is optional in the original schema, there is no indication of that in the new schema, since FEEL has no conception of optional elements. Our test case instance, using the new schema, looks like this:

And when we execute the model using this XML input, we get the same result as before. In other words, Trisotech is able to transform XML input in either format - "normal" XML valid per the XSD, or its TCK equivalent - into the FEEL input data element Loan Summary. The advantage of the TCK format becomes apparent when your decision model is based purely on FEEL, with spaces in the variable names. In that case, the only XML that works is the TCK format, since "normal" XML does not allow spaces in variable names.
FEEL and XML also differ with respect to optional elements, meaning elements that may be missing in valid XML instances. They are quite common in XSD but do not exist in FEEL item definitions. In the XML instance, missing elements are simply omitted altogether, but in the Trisotech Decision Modeler Execution/Test panel, they are always listed. If you leave them blank, they are passed to the engine with the value null, which is just what you want. (If you enter the value null, they are passed as the string "null", which is NOT what you want!)
On execution, if XML in either the XSD or TCK format is provided with an optional element missing, the corresponding item definition element is passed to the DMN engine with the value null, which is correct. The TCK format also provides an alternative format for missing elements. Instead of the xsi:type attribute, you need to write xsi:nil="true" and leave the value empty. For example, to omit the optional element LTVPct, your XML would include
<component name="LTVPct"><value xsi:nil="true"/></component>I've been focusing on XML because source data is more often specified as XSD, but in practice most often REST service calls use JSON instead. For example, the OpenAPI button in the Service Library downloads the service interface specification in JSON format. Some developers will tell you they love JSON and absolutely hate XML, but to me they are effectively equivalent. JSON syntax is more compact than XML, as seen by the equivalent test case below.
Not only is JSON more compact, but the component names may contain spaces. Also, a JSON element, as in FEEL, may be specified as an array of unnamed items. So in many respects, FEEL data is more like JSON than XML, and you may find JSON a more convenient format for testing your deployed decision services. Either way, once you've finished modeling your decisions using FEEL, in order to execute the resulting decision services from an external client, you will need to convert your input data to XML or JSON.